

Je cherchais un moyen simple, sans abonnement, sans clé API, et surtout sans me prendre la tête, de tester l'intelligence artificielle, en français!
En plus, je n'ai pas de GPU dans mon serveur, il y a contrôleur PCI avec un NVME à la place. C'était pas gagné. Je savais qu'il y avait des modèles qui pouvaient tourner sans GPU mais je n'y connais pas grand chose.
Après de solides recherches, je tombe sur Serge - LLaMA made easy 🦙!
Si ça c'est pas le god mode de l'installation facile d'une IA, je suis un phoque croisé avec une hyène! C'est super rapide, le téléchargement des modèles dépendent de la vitesse de votre connexion. Il y a des pavés de 42 Go, de mémoire.
Je voulais vous partager cette petite trouvaille!
Par contre je sais que mon expérience sera brève dans ce domaine vu mon CPU, par moment j'ai cru qu'il allait tuer toute la famille en explosant. J'ai un Intel(R) Core(TM) i3-9100F CPU @ 3.60GHz et j'ai mis pour la VM... 16 Go de RAM.
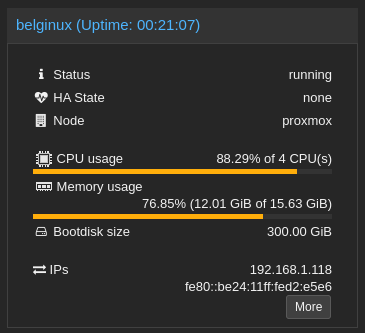
Proxmox ☠️ :
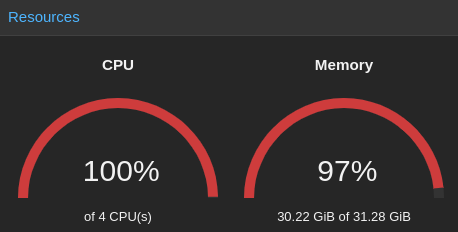
Alors oui, ça fonctionne même avec un CPU tout pourri, sans GPU. Mais c'est un "peu" lent.
Voici les modèles supportés:
| Category | Models |
|---|---|
| Alfred | 40B-1023 |
| Code | 13B, 33B |
| CodeLLaMA | 7B, 7B-Instruct, 7B-Python, 13B, 13B-Instruct, 13B-Python, 34B, 34B-Instruct, 34B-Python |
| Falcon | 7B, 7B-Instruct, 40B, 40B-Instruct |
| LLaMA 2 | 7B, 7B-Chat, 7B-Coder, 13B, 13B-Chat, 70B, 70B-Chat, 70B-OASST |
| Med42 | 70B |
| Medalpaca | 13B |
| Medicine-LLM | 13B |
| Meditron | 7B, 7B-Chat, 70B |
| Mistral | 7B-V0.1, 7B-Instruct-v0.2, 7B-OpenOrca |
| MistralLite | 7B |
| Mixtral | 8x7B-v0.1, 8x7B-Dolphin-2.7, 8x7B-Instruct-v0.1 |
| Neural-Chat | 7B-v3.3 |
| Notus | 7B-v1 |
| Notux | 8x7b-v1 |
| OpenChat | 7B-v3.5-1210 |
| OpenLLaMA | 3B-v2, 7B-v2, 13B-v2 |
| Orca 2 | 7B, 13B |
| Phi 2 | 2.7B |
| Python Code | 13B, 33B |
| PsyMedRP | 13B-v1, 20B-v1 |
| Starling LM | 7B-Alpha |
| Vicuna | 7B-v1.5, 13B-v1.5, 33B-v1.3, 33B-Coder |
| WizardLM | 7B-v1.0, 13B-v1.2, 70B-v1.0 |
| Zephyr | 3B, 7B-Alpha, 7B-Beta |
J'en ai profité pour poser une question existentielle:

L'installation
- Créez votre docker-compose.yml:
nano docker-compose.yml- Collez ça dedans en prenant soin d'adapter le port et les volumes suivant votre configuration:
services:
serge:
image: ghcr.io/serge-chat/serge:latest
container_name: serge
restart: unless-stopped
ports:
- 8008:8008
volumes:
- /srv/appdata/serge/weights:/usr/src/app/weights
- /srv/appdata/serge/datadb:/data/db/- On installe l'application:
docker-compose up -d
ou avec docker-compose V2:
docker compose up -d- Rendez-vous sur l'ip:port, suivant l'IP de votre serveur local et le port choisi:
http://ip:8008
Tel quel, il ne sera pas bavard. Il faut télécharger un modèle au préalable.
Télécharger un modèle
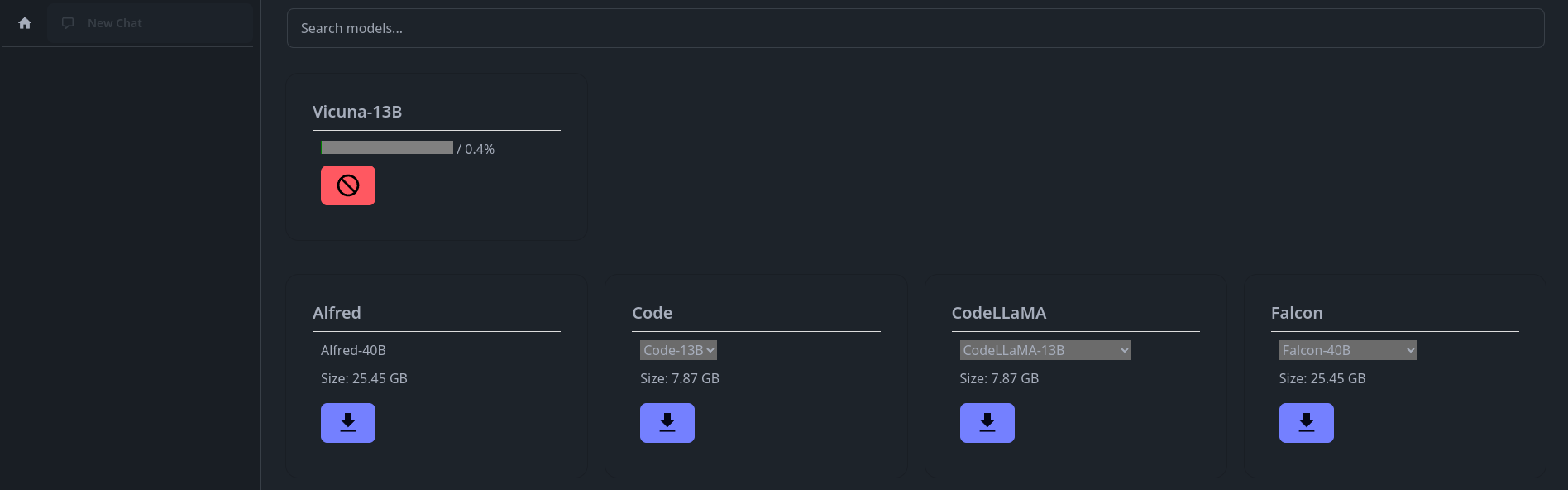
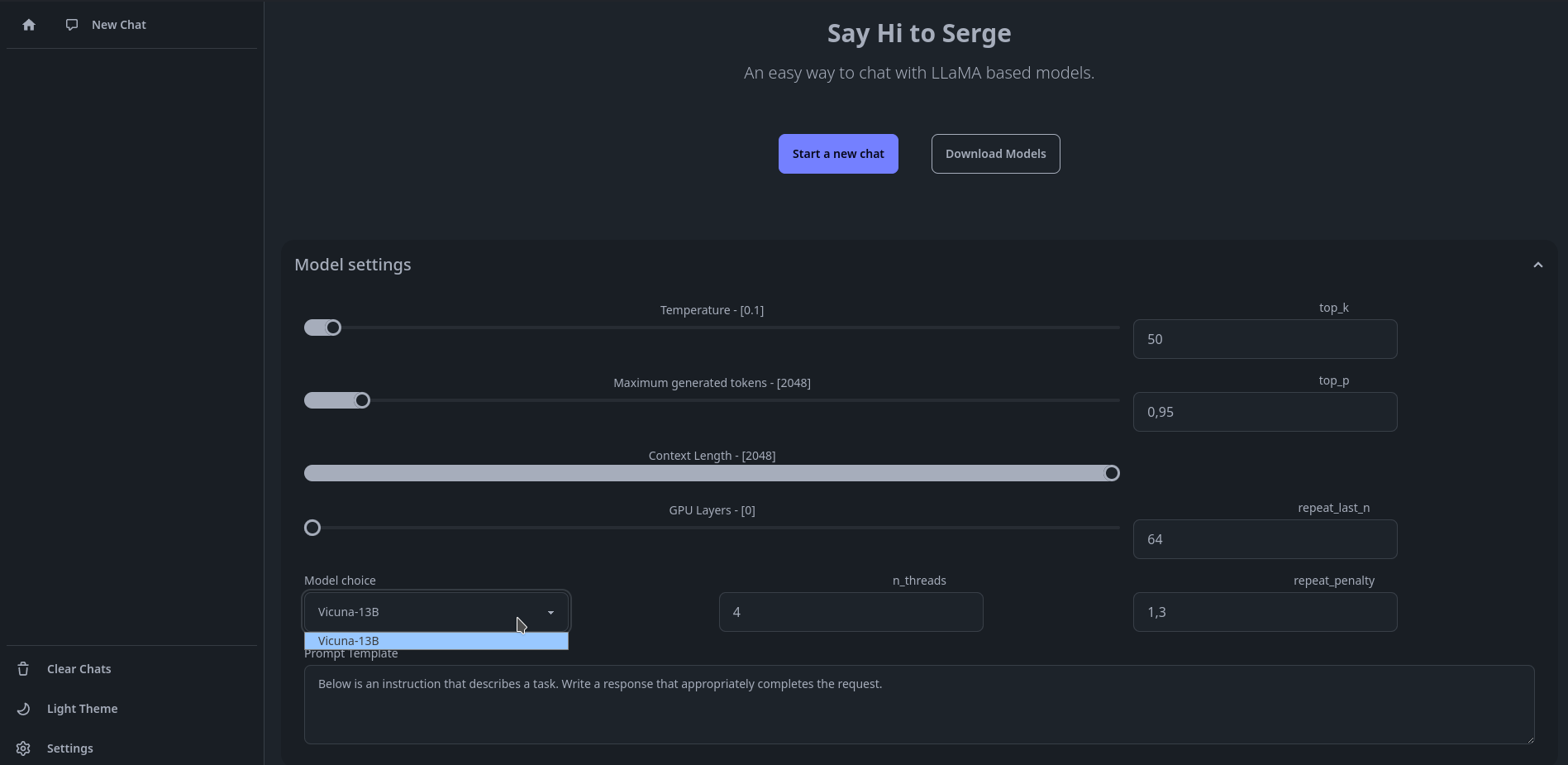
Une fois sur la page d'accueil , cliquez sur Download Models, faites votre choix, vous pouvez très bien tous les prendre, mais bonjour la place, renseignez-vous un peu sur le net pour comprendre les différences entre l'un et l'autre:

Personnellement, je suis une quiche en IA et modèles, je me suis un peu renseigné et j'ai pris le modèle Vicuna, je sais qu'il parle français, ainsi que d'autres, mais lui c'est certain.

Cliquez sur la flèche pour le télécharger, vous pouvez voir sa progression en haut de la page:
Une fois qu'il est téléchargé, vous pouvez commencer à "discuter" avec.
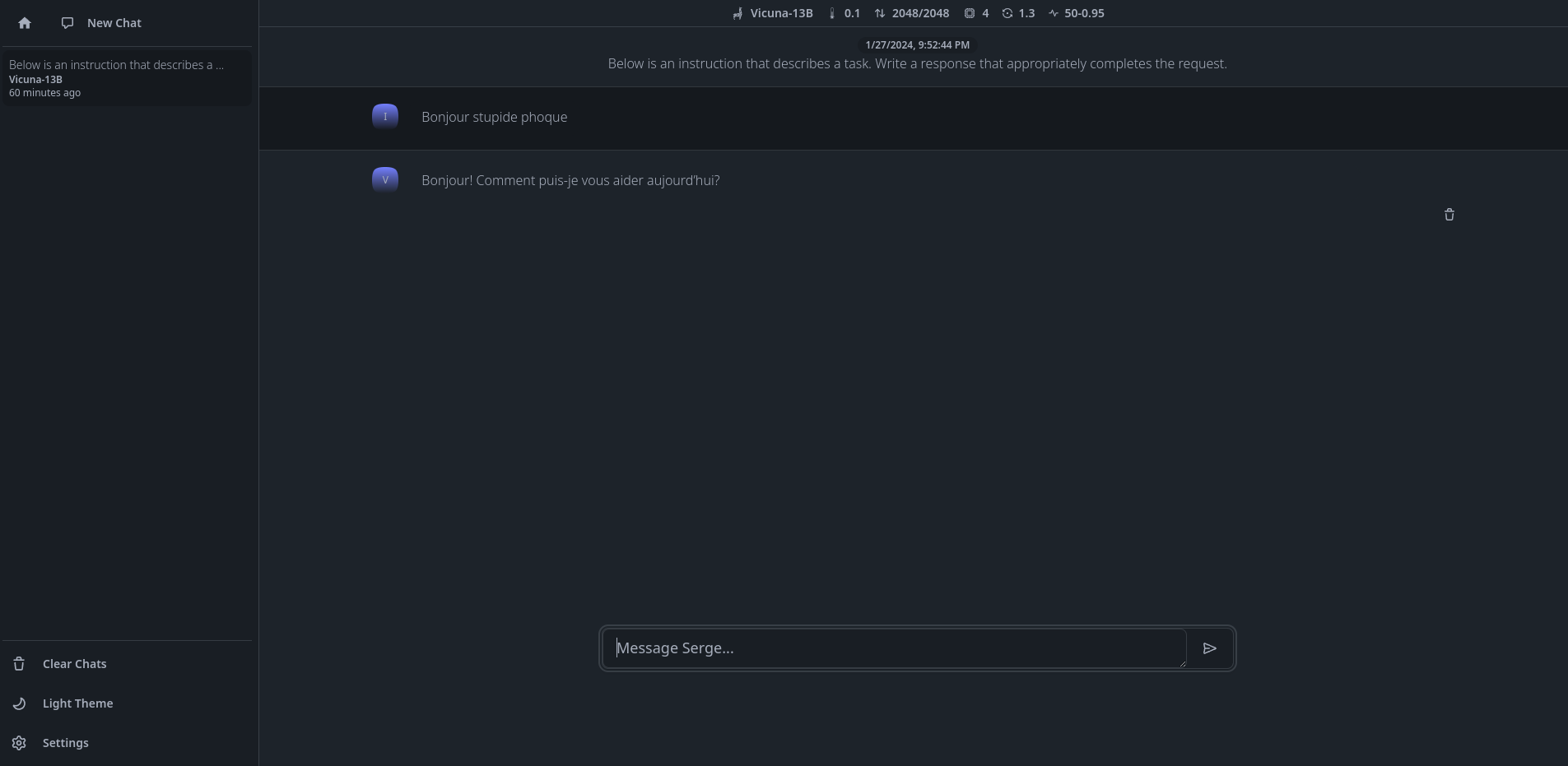
Prévenez vos proches que tout va bien dans votre tête. On ne sait jamais.
Créer un nouveau chat
Une fois que votre modèle est téléchargé, cliquez sur la Maison en haut à gauche, ensuite sur New Chat:
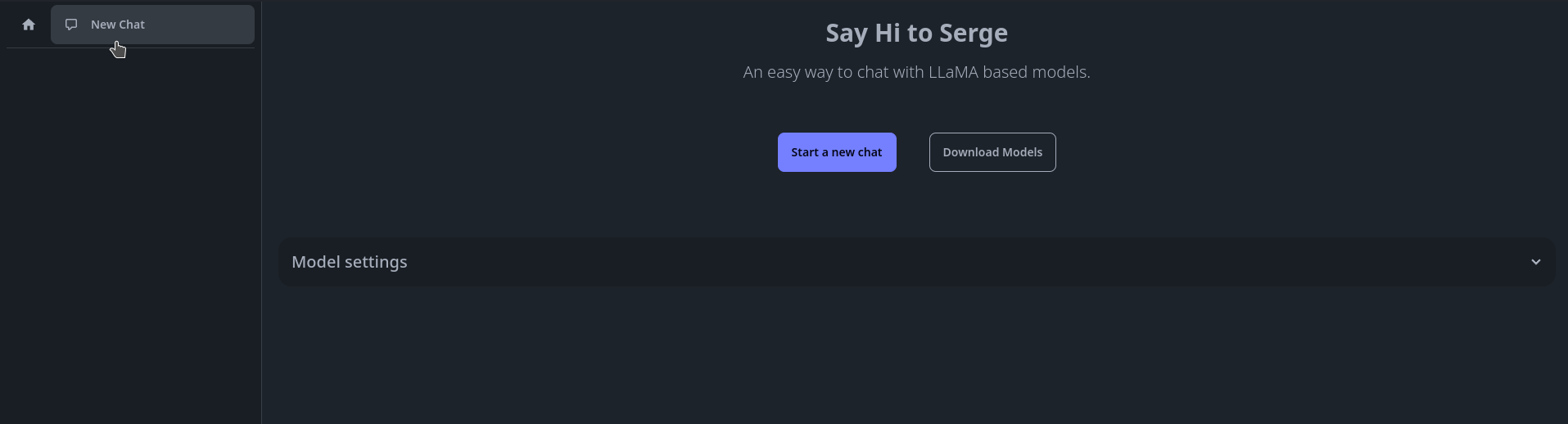
Si vous n'avez qu'un modèle, vous pouvez directement cliquer sur Start a new chat, si vous avez plusieurs modèles, il faudra le sélectionner dans Model settings, puis cliquez sur Start a new chat:
Et pas vite vexé avec ça. 😃




{kind=link}